

In order to understand how Google crawler works we must first know what actually the crawler is.
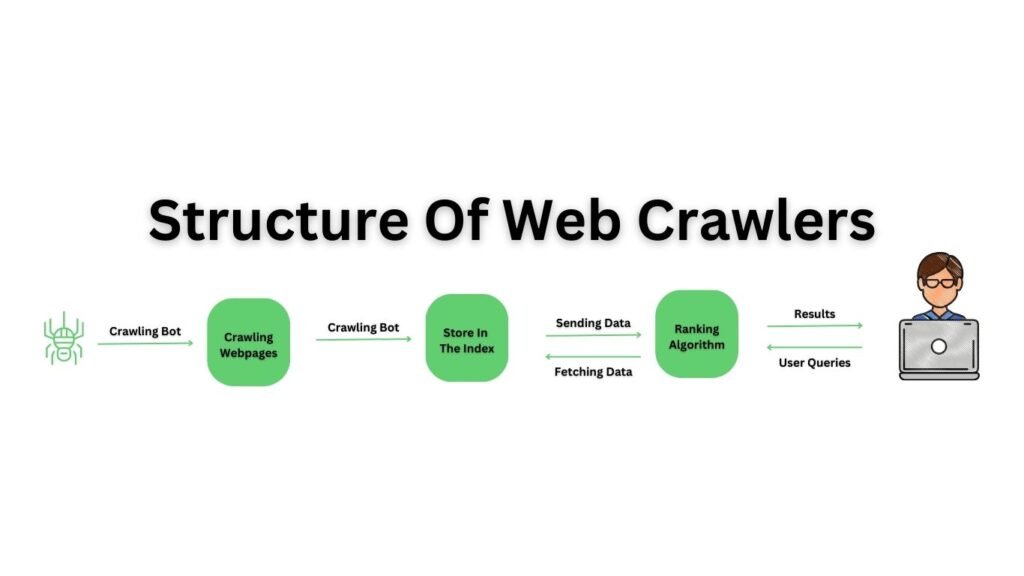
At the core of Google’s search process lie two essential steps: crawling and indexing. First, Google scans the web in search of new web pages, a process known as crawling. Once these pages are discovered, Google indexes them, comprehending their content to determine how they should be ranked in search results. While crawling and indexing represent separate procedures, both tasks are executed by a web crawler.
In our comprehensive guide, we have compiled everything that an SEO specialist should grasp about web crawlers. Dive in to discover what the Google crawler is, understand its functioning, and explore strategies to enhance its interaction with your website. By optimizing this process, you can ensure that crawling issues never become the cause of a drop in your search rankings.
What is Google crawler?
The Google crawler, also referred to as a searchbot or spider, is a software tool employed by Google and other search engines to systematically explore the internet. In simpler terms, it navigates from one webpage to another, actively seeking fresh or recently modified content that has not yet been incorporated into Google’s databases.
Every search engine operates with its own array of web crawlers. In the case of Google, it utilizes over 15 distinct types of crawlers, with the primary one being named Googlebot. Googlebot fulfills the dual roles of crawling and indexing. Therefore, we’ll delve deeper into understanding its functioning.
How does Google crawler work?
Google, and essentially any other search engine, doesn’t maintain a central registry of URLs that is automatically updated whenever a new page is generated. This implies that Google doesn’t receive automatic alerts about new pages; instead, it has to explore the web to discover them. Googlebot continually roams the internet, actively searching for fresh pages to incorporate into Google’s existing database of webpages.
Once Googlebot locates a new page, it proceeds to render (visually display) the page within a web browser, fully loading all the HTML, JavaScript, third-party code, and CSS elements. This comprehensive data is saved in the search engine’s database and subsequently employed for the processes of indexing and ranking the page. When a page has been successfully indexed, it becomes a part of the vast Google Index, which constitutes yet another extensive database maintained by Google.
Some Examples of Web Crawlers
Major search engines employ their own web crawlers, each designed with a specific algorithm to collect data from webpages. These web crawler tools can be either desktop-based or cloud-based. Here are some instances of web crawlers utilized in search engine indexing:
- Amazonbot: Amazon’s dedicated web crawler.
- Bingbot: Microsoft’s web crawler designed for Bing.
- DuckDuckBot: The crawler responsible for DuckDuckGo’s search engine.
- Googlebot: The web crawler employed by Google’s search engine.
- Yahoo Slurp: Yahoo’s search engine relies on this web crawler.
- Yandex Bot: The web crawler utilized by the Yandex search engine.
How does Google crawler View pages?
The Google crawler uses the most current version of the Chromium browser to render a page. In an ideal situation, the Google crawler views a page exactly as it was designed and constructed. However, in practical terms, things are not that easy.
Mobile and desktop rendering
Googlebot employs two distinct types of crawlers to “view” your webpage: Googlebot Desktop and Googlebot Smartphone. This division is essential to ensure that pages are indexed for both desktop and mobile Search Engine Results Pages (SERPs).
In the past, Google primarily utilized a desktop crawler to visit and render the majority of web pages. However, there has been a significant shift with the introduction of the mobile-first concept. Google recognized that the world had become sufficiently mobile-friendly, prompting the adoption of Googlebot Smartphone for crawling, indexing, and ranking the mobile versions of websites for both mobile and desktop SERPs.
However, the implementation of mobile-first indexing proved to be more challenging than initially anticipated. The vast expanse of the internet revealed that most websites were inadequately optimized for mobile devices. Consequently, Google began employing the mobile-first concept for crawling and indexing new websites, as well as those older sites that had become fully optimized for mobile use. For websites that are not mobile-friendly, Google’s initial approach involves crawling and rendering them with Googlebot Desktop.
Even if your website has transitioned to mobile-first indexing, some of your pages may still be crawled by Googlebot Desktop. Google does not explicitly state that it will index your desktop version if it significantly differs from the mobile one. However, it’s reasonable to assume this, given that Google’s foremost objective is to furnish users with the most valuable information. Google is unlikely to forgo potentially useful information by rigidly adhering to the mobile-first concept.
Regardless of the scenario, your website will be accessed by both Googlebot Mobile and Googlebot Desktop. Therefore, it is crucial to ensure that both versions of your website are well-maintained. Consider implementing a responsive layout if you haven’t already done so.
To determine whether Google is crawling and indexing your website using the mobile-first concept, keep an eye on your Google Search Console. You will receive a special notification in this tool that provides valuable insights into the indexing process.
How can you confirm that your site is in the mobile-first index in Google search console?
Open Google Search Console and initiate a URL inspection for one of your website’s pages. Enter the URL into the text box located at the top of your screen. Pay attention to how it is crawled and indexed as “Googlebot smartphone.” This simple and efficient method allows you to monitor how Google is crawling your site, confirming that it is employing a mobile-first approach.
How to Verify if your website is listed on Google Search?
- Visit google.com.
- In the search bar, enter site: followed by your website’s URL.
- If your website shows up, you’re good to go. If not, submit your website to Google via Google Search Console.
HTML and JavaScript rendering
Googlebot might encounter difficulties when processing and rendering extensive code. If your page’s code is disorganized, the crawler might struggle to render it correctly and perceive your page as empty.
Regarding JavaScript rendering, it’s important to note that JavaScript is a rapidly advancing language, and Googlebot may occasionally struggle to support the latest versions. Ensure your JavaScript is compatible with Googlebot to avoid incorrect rendering of your page.
Pay close attention to the loading time of your JavaScript. If a script on your website takes more than 5 seconds to load, Googlebot won’t be able to properly render and index the content generated by that script. It’s essential to optimize your website’s JavaScript to ensure efficient loading and indexing by Googlebot.
If your website heavily relies on JavaScript elements that are integral to its functionality, Google recommends implementing server-side rendering. This approach enhances your website’s loading speed and minimizes JavaScript-related issues.
To identify which resources on your webpage might be causing rendering problems, and to check for any potential issues, follow these steps:
- Log in to your Google Search Console account.
- Navigate to the “URL Inspection” tool.
- Enter the specific URL you want to examine.
- Click the “Test Live URL” button.
- Select “View Tested Page.”
- In the “More Info” section, explore the “Page Resources” and “JavaScript Console Messages” folders to access a list of resources that Googlebot may have had difficulty rendering.
Now, with the list of problems that could be causing issues with how your webpage appears, you can talk to the people who manage your website, like web developers or site administrators. Share this list of issues with them and ask for their help in finding and fixing these errors. By working together, you can make sure that Googlebot shows your website correctly, which will improve how it appears in search results.
What influences the crawler’s behavior?
Googlebot’s actions are not random; they follow well-designed algorithms that guide the crawler as it explores the internet and processes information. However, you shouldn’t simply leave it to chance and hope for the best. It’s essential to understand what factors affect Googlebot’s behavior and learn how to make your web pages more crawler-friendly. Let’s delve into these influences and explore ways to optimize how your pages are crawled.
Internal links and backlinks
If Google is already familiar with your website, Googlebot periodically checks your primary pages for updates. Therefore, it’s vital to include links to new pages, ideally on your homepage or other authoritative pages. Enhancing your homepage with a section featuring the latest news or blog posts, even if you maintain separate news and blog pages, can speed up Googlebot’s discovery of your new content. This may sound obvious, but many website owners overlook it, leading to slower indexing and lower search rankings.
Backlinks operate on the same principle for crawling. If your page is linked from a credible and popular external source, Google will find it more quickly. So, when you create a new page, remember to promote it externally. You can explore options like guest posting, running advertising campaigns, or utilizing other methods you prefer to ensure Googlebot detects the URL of your new page.
For Googlebot to follow links, they should be dofollow. While Google has mentioned that nofollow links can also serve as hints for crawling and indexing, it’s still advisable to use dofollow links to ensure that Google crawlers can access the page.
Click depth or Page depth
Click depth refers to how many “steps” Googlebot needs to take to reach a page from the homepage, indicating how far a page is within a website’s structure. Ideally, any page on your website should be reachable within just 3 clicks. When click depth is excessive, it can slow down crawling and harm user experience.
Sitemap
A sitemap is like a roadmap that contains a comprehensive list of all the pages on your website that you want Google to know about. You can share this sitemap with Google through Google Search Console (simply go to Index > Sitemaps) to inform Googlebot about which pages it should explore and crawl. Additionally, a sitemap helps Google identify any updates or changes on your pages.
It’s important to note that having a sitemap doesn’t guarantee that Googlebot will exclusively follow it during crawling; the crawler may still choose its own path. However, there’s no penalty for having a sitemap, and in many cases, it proves to be beneficial. Some Content Management Systems (CMSs) even generate and update sitemaps automatically, sending them to Google to streamline your SEO efforts. Consider submitting a sitemap, especially if your website is new or extensive (with more than 500 URLs).
Indexing instructions
During the process of crawling and indexing your web pages, Google adheres to specific directives provided by various sources, which include the robots.txt file, the noindex tag, the robots meta tag, and the X-Robots-Tag.
The robots.txt file is a document located in the root directory of your website that serves to limit or block certain pages or content elements from being indexed by Google. When Googlebot encounters one of your pages, it first checks the robots.txt file. If the content of the discovered page is designated as off-limits for crawling by robots.txt, Googlebot promptly ceases its crawling and refrains from loading any content or scripts from that particular page. Consequently, this page will not show up in search results.
The noindex tag, robots meta tag, and X-Robots-Tag are all utilized to restrict the accessibility of a webpage to web crawlers and influence its indexing status.
- A noindex tag, as its name suggests, prevents the page from being indexed by all types of crawlers, essentially excluding it from search engine results.
- The robots meta tag provides a more nuanced approach, allowing you to specify how a particular page should be crawled and indexed. This means you can selectively block certain types of crawlers from accessing the page while leaving it open to others.
- The X-Robots-Tag, on the other hand, operates as an element within the HTTP header response. It serves the purpose of either restricting the page from indexing or influencing the behavior of crawlers on the page. This tag offers the advantage of targeting specific types of crawling robots if specified. In cases where the robot type is not explicitly defined, the instructions provided will apply to all Google crawlers.
It’s essential to note that while the robots.txt file exists to guide crawlers, it doesn’t provide an absolute guarantee that a page will be excluded from indexing. Googlebot, in particular, treats the robots.txt file as more of a recommendation than a strict order. Consequently, Google may choose to disregard robots.txt and index a page for search. To ensure a page remains unindexed, using a noindex tag is the more reliable option.
Can All Pages Be Crawled and Indexed by Google?
No, not all pages are accessible for crawling and indexing by Google. Let’s take a closer look at the different types of pages that may be unavailable for these processes:
- Password-Protected Pages: When a page is shielded behind a password, Googlebot behaves like an anonymous user without the necessary credentials to access the protected content. Consequently, such pages remain uncrawled since Googlebot cannot gain entry.
- Pages Excluded by Indexing Instructions: These pages are intentionally hidden from Google based on specific instructions. This includes pages governed by robots.txt guidelines, as well as pages that carry a noindex tag, robots meta tag, or X-Robots-Tag.
- Orphan Pages: Orphan pages are those that lack links from other pages within the same website. Googlebot functions as a spider-robot, discovering new pages by diligently following links it encounters. When no other pages link to a specific page, it goes unnoticed, remaining uncrawled and absent from search results.
While certain pages are intentionally restricted from crawling and indexing, like those containing personal data, policies, terms of use, test versions, archive pages, and internal search results, there are other pages intended for public access. To ensure your pages are readily available for Google’s crawlers and can attract organic traffic, be cautious about password-protecting public pages, manage your internal and external linking, and carefully review your indexing instructions.
To assess the crawlability of your website’s pages using Google Search Console, navigate to the “Index” section and access the “Coverage Report.” Pay special attention to pages marked as “Error” (not indexed) and “Valid with warning” (indexed but with potential issues).
Note: If there are pages you prefer Googlebot not to find or update, such as older or obsolete pages, consider the following actions:
- If you have a sitemap, remove these pages from it.
- Set up a “404 Not Found” status for these pages.
- Apply a “noindex” tag to these pages to signal to search engines that they should not be indexed.
When Will My Website Appear in Search Results?
It’s important to understand that your web pages won’t instantly show up in search results as soon as your website goes live. If your website is brand new, it may take some time for Googlebot to discover it on the web. Be aware that this “some time” can occasionally extend to as long as 6 months in certain cases.
If Google is already aware of your website and you’ve made updates or added new pages, the speed at which these changes appear on the web is influenced by what’s known as your crawl budget.
What is a Crawl Budget?
Your crawl budget is the amount of resources that Google dedicates to crawling your website. The more resources Googlebot requires to crawl your website, the slower your changes will be reflected in search results.
Several factors affect how your crawl budget is allocated:
- Website Popularity: A more popular website receives a higher allocation of crawling resources from Google.
- Update Frequency: Websites that update their pages frequently receive a larger share of crawling resources.
- Number of Pages: Websites with a greater number of pages are granted a larger crawl budget.
- Server Capacity: Your hosting servers must be able to promptly respond to crawler requests.
It’s important to note that the crawl budget is not distributed equally among all your pages. Some pages, due to factors like heavy JavaScript, CSS, or messy HTML, consume more resources. Consequently, your allocated crawl budget may not be sufficient to crawl all your pages as swiftly as you might expect.
In addition to issues related to complex code, poor crawling and inefficient crawl budget management often result from problems such as duplicate content and poorly structured URLs.
Duplicate content issues
Duplicate content arises when multiple pages on your website contain nearly identical content. This can occur due to various reasons, such as:
- Accessing the page through different methods: For example, with or without “www,” using HTTP or HTTPS.
- Dynamic URLs: When several distinct URLs lead to the same page.
- A/B Testing: Testing different versions of pages.
Failure to address duplicate content can result in Googlebot crawling the same page multiple times, treating them as distinct pages. Consequently, valuable crawling resources are wasted, and Googlebot may struggle to discover other meaningful pages on your site. Furthermore, duplicate content can negatively impact your page rankings in search results, as Google might perceive your website’s overall quality as lower.
While you may not always be able to eliminate the causes of duplicate content, you can prevent such issues by implementing canonical URLs. A canonical tag signals which page should be considered the “primary” one, instructing Google not to index other URLs pointing to the same page, thereby eliminating content duplication. Additionally, you can prevent crawling robots from accessing dynamic URLs by using the robots.txt file.
Addressing URL Structure Issues
Both humans and search engine algorithms, including Googlebot, appreciate user-friendly URLs. Googlebot can sometimes encounter confusion when dealing with lengthy, parameter-rich URLs. The more “confused” Googlebot becomes, the more crawling resources it consumes on a single page.
To avoid unnecessary expenditure of your crawling budget, ensure that your URLs are user-friendly. User (and Googlebot)-friendly URLs are clear, follow a logical structure, utilize appropriate punctuation, and avoid complex parameters. In essence, your URLs should resemble the following format:
http://website.com/vegetables/Mango/pickles
It’s worth noting that crawl budget optimization is generally a concern for owners of large websites (1 million+ pages) or medium-sized sites (10,000+ pages) with frequently changing content (daily or weekly). For most other cases, proper website optimization for search and timely resolution of indexing issues should suffice.
Why Web Crawlers Are Important For SEO?
Now let’s talk a little bit about why web crawlers are so important for SEO, which is all about making a website more visible when people search for things online.
Imagine a scenario: if a website has problems that make it hard for these web crawlers to explore it, or if the crawlers can’t explore it at all, that website will end up with lower rankings in search results. Sometimes, it might not even show up in search results at all. This is why it’s crucial to make sure webpages don’t have issues like broken links, and to let web crawler bots access the site without any roadblocks.
But that’s not all. Web crawlers also need to visit a website regularly. Why? Because this helps in keeping the website up-to-date. If a website isn’t visited often by these crawlers, it won’t show any recent changes or updates. Regular visits and updates are especially important for content that relates to current events or time-sensitive topics. All of this helps in making a website perform better in online searches.
Conclusion
Google’s primary crawler, Googlebot, operates using advanced algorithms, but you can still influence its behavior to benefit your website. Furthermore, many of the steps involved in optimizing the crawling process align with standard SEO practices that we’re all familiar with.
If you have any questions, feel free to ask in the comments.
You may like to read: What Is SEO – Search Engine Optimization – Everything You Need To Know